







概要:在日常的办公过程中,我们很多场景都需要与 PDF 文档打交道,也需要对 PDF 文档做各种操作,比如格式转换、数据提取等等。今天就给大家介绍一下如何批量提取多个 PDF 文档中的图片的方法!
PDF 文档中有很多元素,比如文本、图片等等,从 PDF 提取图片是指将 PDF 文档中的图片导出来,而不是直接将 PDF 文档导出为图片,这里需要大家注意区分两者的区别!如果需要批量提取多个 PDF 文档中的图片,我们该怎么做呢?
效果预览
今天给大家介绍的是使用「我的ABC软件工具箱」批量提取多个 PDF 文档中的图片的方法,我们先看下效果预览。
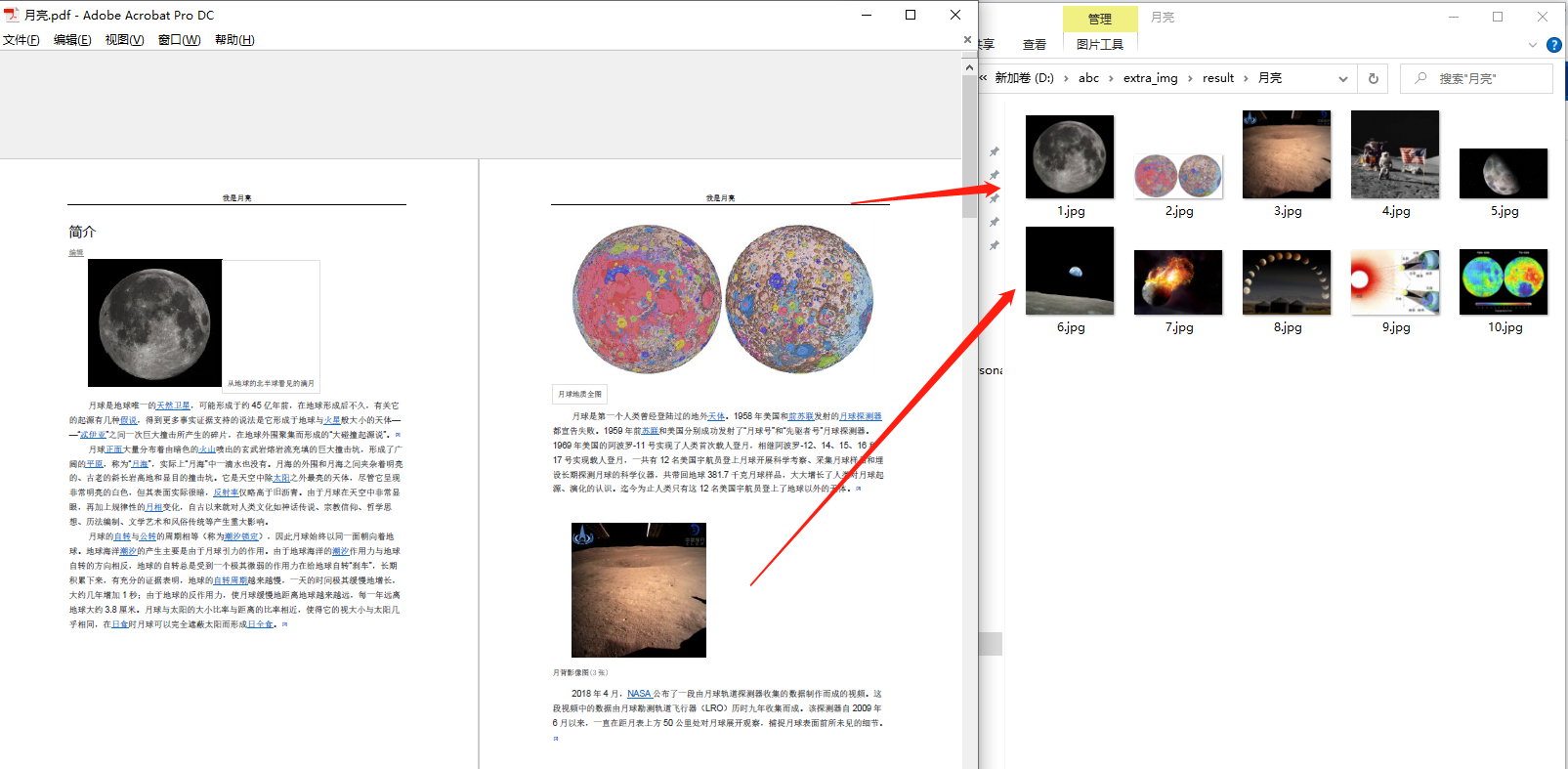
这里能看到文档中所有的图片都已经被提取到了一个文件夹中!我们来看下批量提取多个 PDF 文档中的图片的具体操作吧!
PDF 文档中有很多元素,比如文本、图片等等,从 PDF 提取图片是指将 PDF 文档中的图片导出来,而不是直接将 PDF 文档导出为图片,这里需要大家注意区分两者的区别!如果需要批量提取多个 PDF 文档中的图片,我们该怎么做呢?
PDF 文档中有很多元素,比如文本、图片等等,从 PDF 提取图片是指将 PDF 文档中的图片导出来,而不是直接将 PDF 文档导出为图片,这里需要大家注意区分两者的区别!如果需要批量提取多个 PDF 文档中的图片,我们该怎么做呢?</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









